Autoencoder
Autoencoder
An autoencoder is a special type of multi layer neural network that is used in unsupervised learning, which given an input, tries to recreate that input using a latent state representation of that input.
Essentially, an autoencoder has two parts. An encoder and a decoder. The encoder encodes the given input into some lower dimensional latent representation. The decoder attempts to recreate the original input as output by decoding the lower dimensional latent representation of that input.
The following is a representation of an Autoencoder.
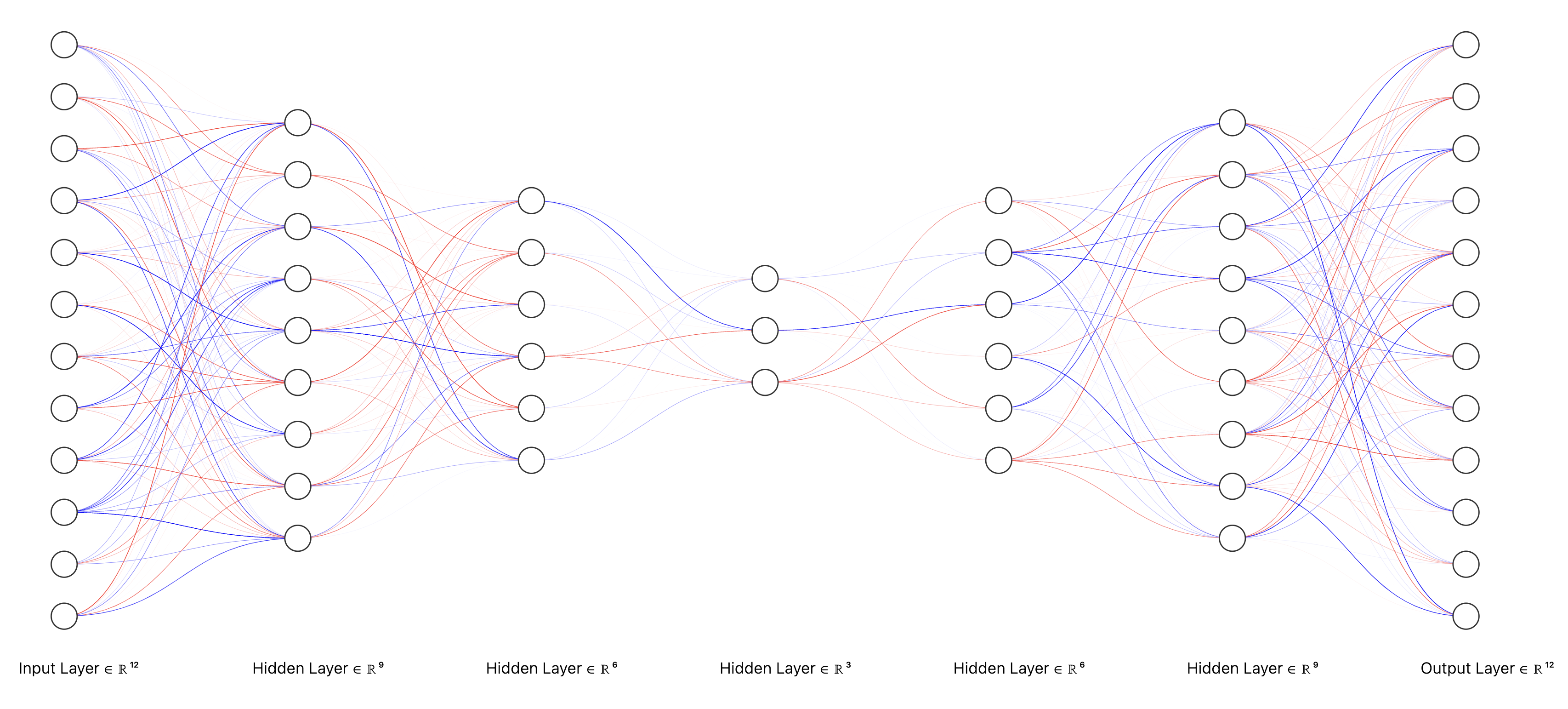
Well, what then is the purpose of an autoencoder? Is the goal to simply be able to copy the input? No! The idea is that autoencoders are designed such that they are restricted in what they can learn about the input data and not memorize it completely. In the diagram above for example, as we go from the left to middle, the encoder has 12, 9, and 6 nodes in each layer. The middle layer which we can call the "latent" layer only has 3 nodes. So in a way, specific features/information from a high dimensional input is being choked and forced to be encoded in just 3 nodes as we get to the middle layer. From there on, the decoder is just the reverse of the encoder. It takes that low dimensional latent representation (3) to 6, 9, and finally 12 nodes.
An implementation of a vanilla autoencoder is here: https://github.com/KrishnaMBhattarai/Autoencoder
You can also open the notebook with Google Colab directly: https://colab.research.google.com/github/KrishnaMBhattarai/Autoencoder/blob/main/autoencoder.ipynb
Vanilla Autoencoders have limitations including potential overfitting to training data, difficulty learning complex data distributions, and the latent space learnt by them is not continuous. Modern variations of Autoencoders known as Variational Autoencoders try to overcome some of these issues by taking this naive and deterministic approach to a more probabilistic approach.